Kafka là gì? Tính năng thông minh và lợi ích của Kafka là gì?
Khám phá | by
Kafka là hệ thống tiếp nhận và xử lý khối lượng dữ liệu lớn nhằm cung cấp thông tin hữu hiệu cho người dùng. Tìm hiểu Kafka là gì? Tính năng Kafka là gì tại đây.
Với sự phát triển nhanh đến chóng mặt của công nghệ, trên phạm vi toàn cầu, con người nếu không kịp thời cập nhật kiến thức về kỹ thuật và công nghệ sẽ rất dễ bị tụt hậu. Do đó mọi người và các doanh nghiệp đang dùng khá nhiều ứng dụng công nghệ cao, điển hình là Kafka. Nhưng liệu mọi người đã biết Kafka là gì chưa?, hãy cùng tech24 khám phá trong bài viết này nhé!
Kafka là gì?

Hệ thống tối ưu hóa dữ liệu để cung cấp thông tin cho nhiều ngành nghề
Kafka là một hệ thống phân tán được tối ưu hóa để tiếp nhận và xử lý dữ liệu theo luồng thời gian thực. Nó có sự tích hợp chặt chẽ giữa việc luân chuyển, lưu trữ và xử lý dữ liệu theo luồng để phân tích dữ liệu trong thời gian thực. Với các tính năng này, Kafka đã trở thành một công cụ quan trọng cho các nguồn cung cấp dữ liệu hiện đại, nhằm truyền dữ liệu giữa các ứng dụng và phân tích dữ liệu một cách chính xác.
Ban đầu, Kafka được phát triển bởi LinkedIn và sau đó trở thành dự án mã nguồn mở của Apache vào năm 2011. Kafka được viết bằng Scala và Java với mục đích cung cấp một nền tảng mạnh mẽ và có hiệu suất cao để xử lý các nguồn cấp dữ liệu theo thời gian thực.
Các thuật ngữ cần biết khi sử dụng Kafka là gì?
Nếu mọi người đang quan tâm đến Kafka thì nhất định phải biết đến những thuật ngữ dưới đây mà tech24 đã tổng hợp lại
Consumer của Kafka là gì?
Tìm hiểu Consumer để biết cách xử lý dữ liệu hiệu quả
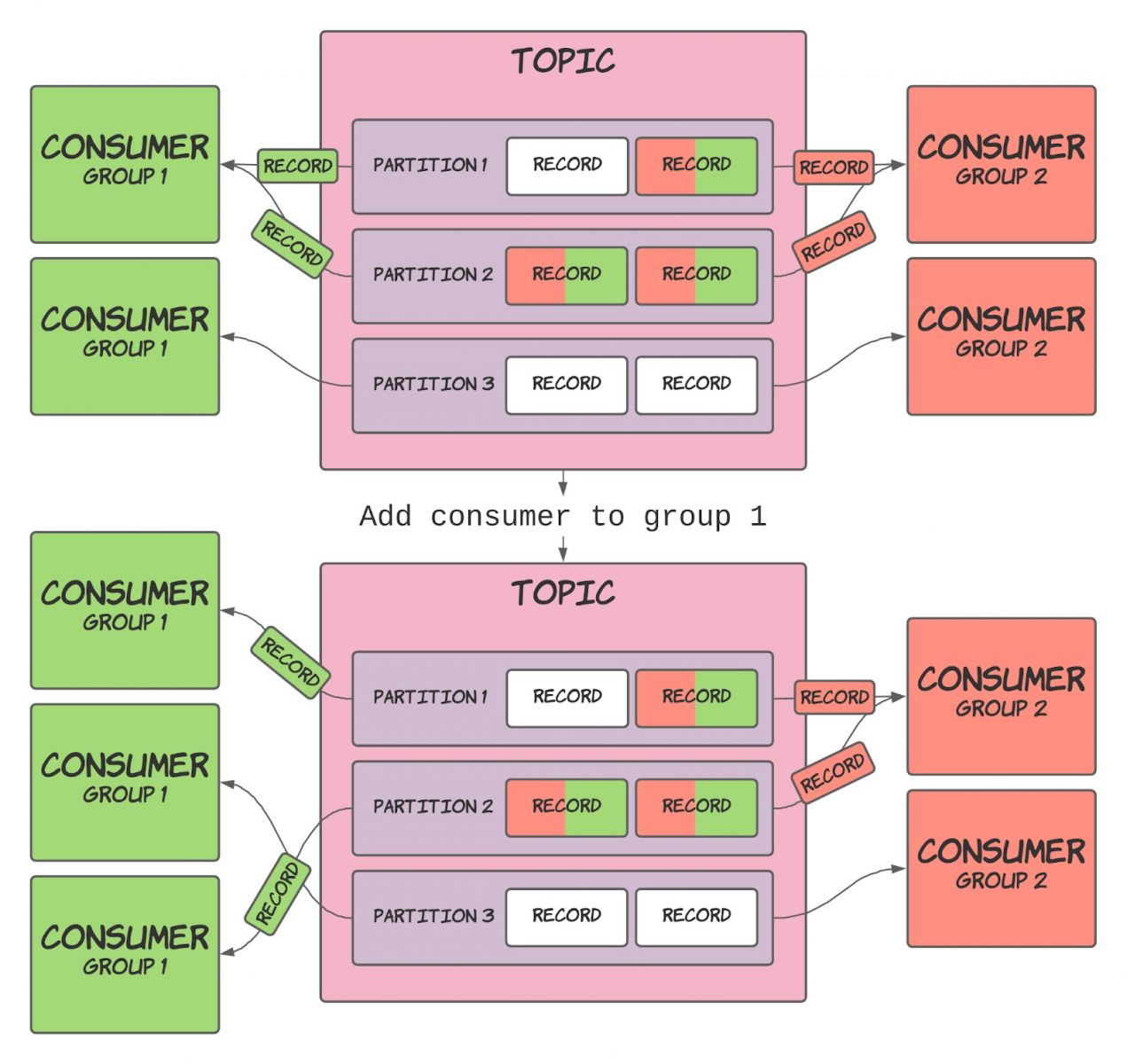
Consumer là một thành phần quan trọng trong Consumer Group (là một nhóm các Consumer tiêu thụ message từ Kafka server.). Khi có nhiều Consumer Subscribe từ một Topic và cùng thuộc một Consumer Group, mỗi Consumer trong group sẽ nhận message từ các Partition khác nhau.
Ví dụ: nếu có một Topic A1 với 4 Partition, và chúng ta tạo một Consumer C1 và chỉ có duy nhất Consumer C1 trong group G1, và Consumer C1 subscribe vào Topic A1, lúc này C1 sẽ nhận tất cả các message từ 4 Partition .
Topic
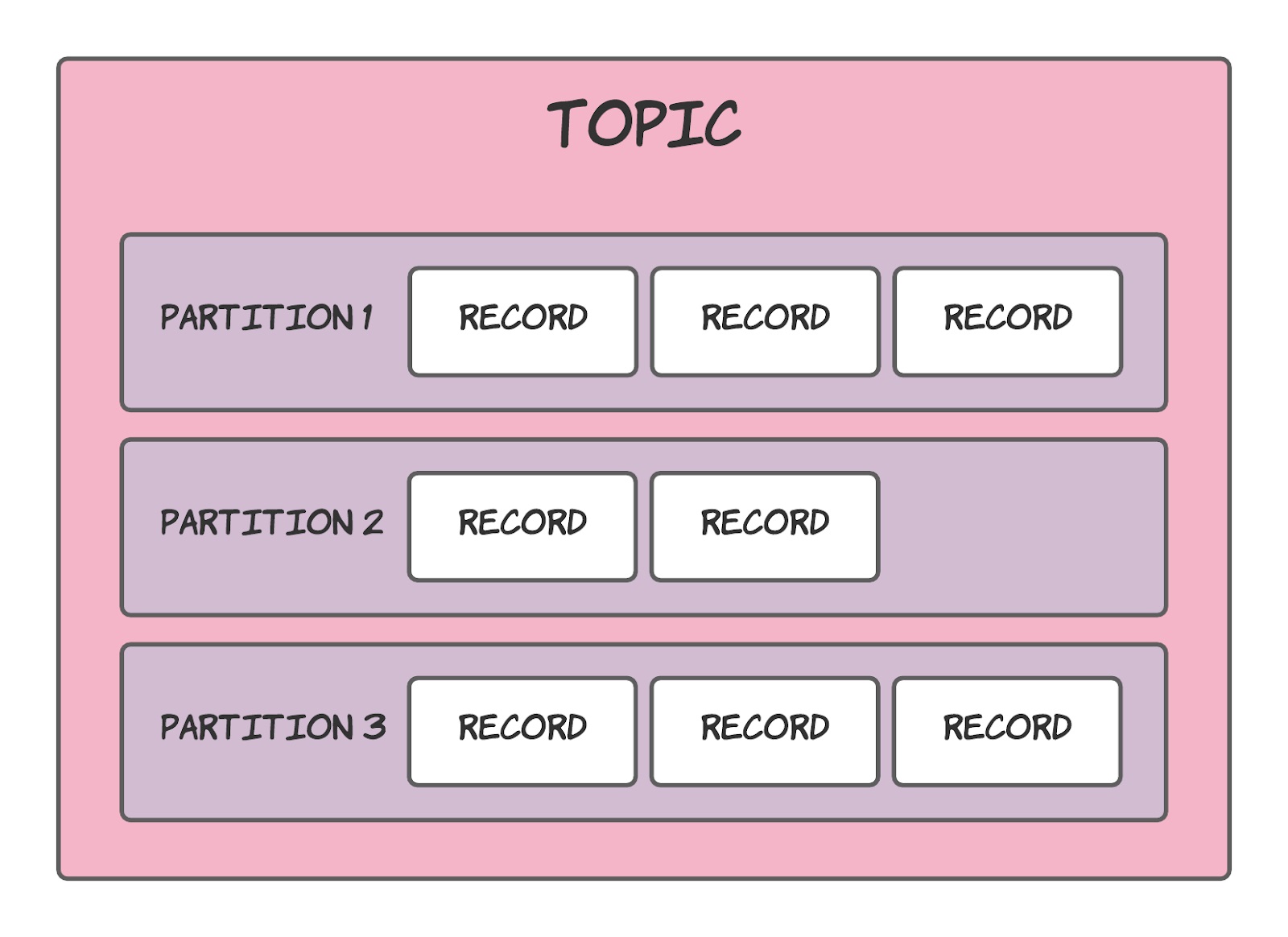
Topic là danh mục lưu trữ thông tin rất hiệu quả
Trong Kafka, một Topic là một danh mục chứa các tin nhắn hoặc sự kiện liên quan. Nó có thể được coi như một thư mục trong hệ thống tệp, trong đó mỗi tin nhắn được xem như một tệp trong thư mục đó. Mỗi Topic có thể có nhiều Partition, và mỗi Partition chứa một phần của dữ liệu trong Topic.
Khi gửi một tin nhắn vào Topic, Kafka sẽ lưu trữ tin nhắn đó vào một hoặc nhiều Partition của Topic đó. Mỗi Partition được lưu trữ trên một Broker trong Kafka cluster. Các Consumer có thể subscribe vào một hoặc nhiều topic để nhận các tin nhắn từ các Partition tương ứng.
Partition
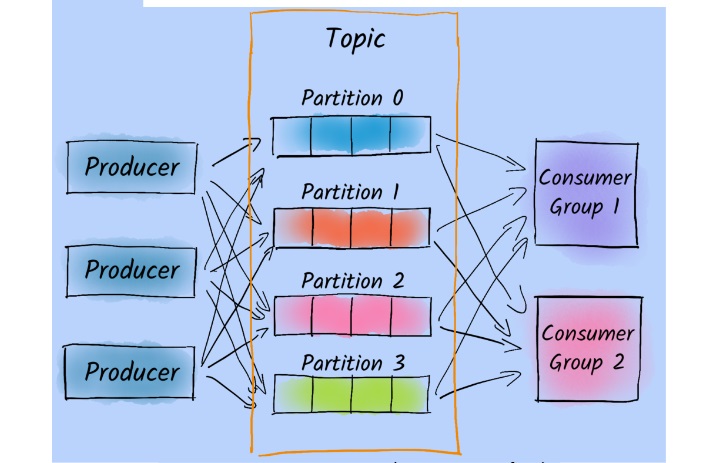
Partition có khả năng lưu trữ và truyền tải thông tin khổng lồ
Đây là nơi dữ liệu được lưu trữ và xử lý, mỗi Topic có thể được chia thành nhiều Partition, và mỗi Partition chứa một phần của dữ liệu trong Topic đó. Mục đích chính của việc chia các partition là để Kafka có thể xử lý dữ liệu một cách phân tán và mở rộng.
Partition cung cấp khả năng mở rộng và tăng hiệu suất xử lý dữ liệu. Nó có thể xử lý các tin nhắn đồng thời trên nhiều Broker và Consumer có thể đọc dữ liệu. Việc này giúp tăng tốc độ xử lý và khả năng chịu tải của hệ thống.
Broker
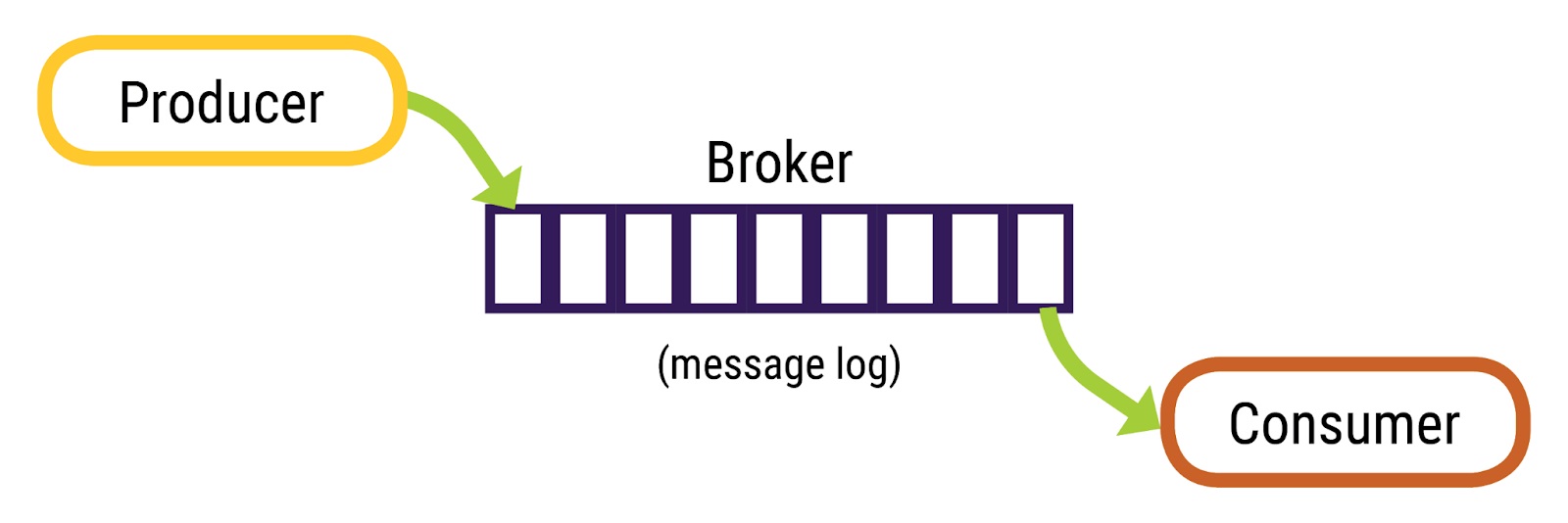
Quá trình truyền dữ liệu từ Producer sang Consumer rất chặt chẽ và logic
Broker là một thành phần quan trọng của hệ thống, mỗi Broker là một máy chủ độc lập trong Kafka Cluster, nơi lưu trữ và xử lý dữ liệu. Một Kafka cluster có thể bao gồm nhiều Broker, và mỗi Broker có thể chứa nhiều Partition của các Topic.
Các broker nhận và lưu trữ các tin nhắn và cung cấp dữ liệu cho Consumer. Mỗi Broker có khả năng xử lý và lưu trữ dữ liệu trên nhiều Partition. Điều này cho phép Kafka xử lý dữ liệu chi tiết và hiệu quả hơn, đồng thời đảm bảo tính toàn vẹn và nhất quán trong quy trình làm việc với dữ liệu.
Cluster Kafka là gì?
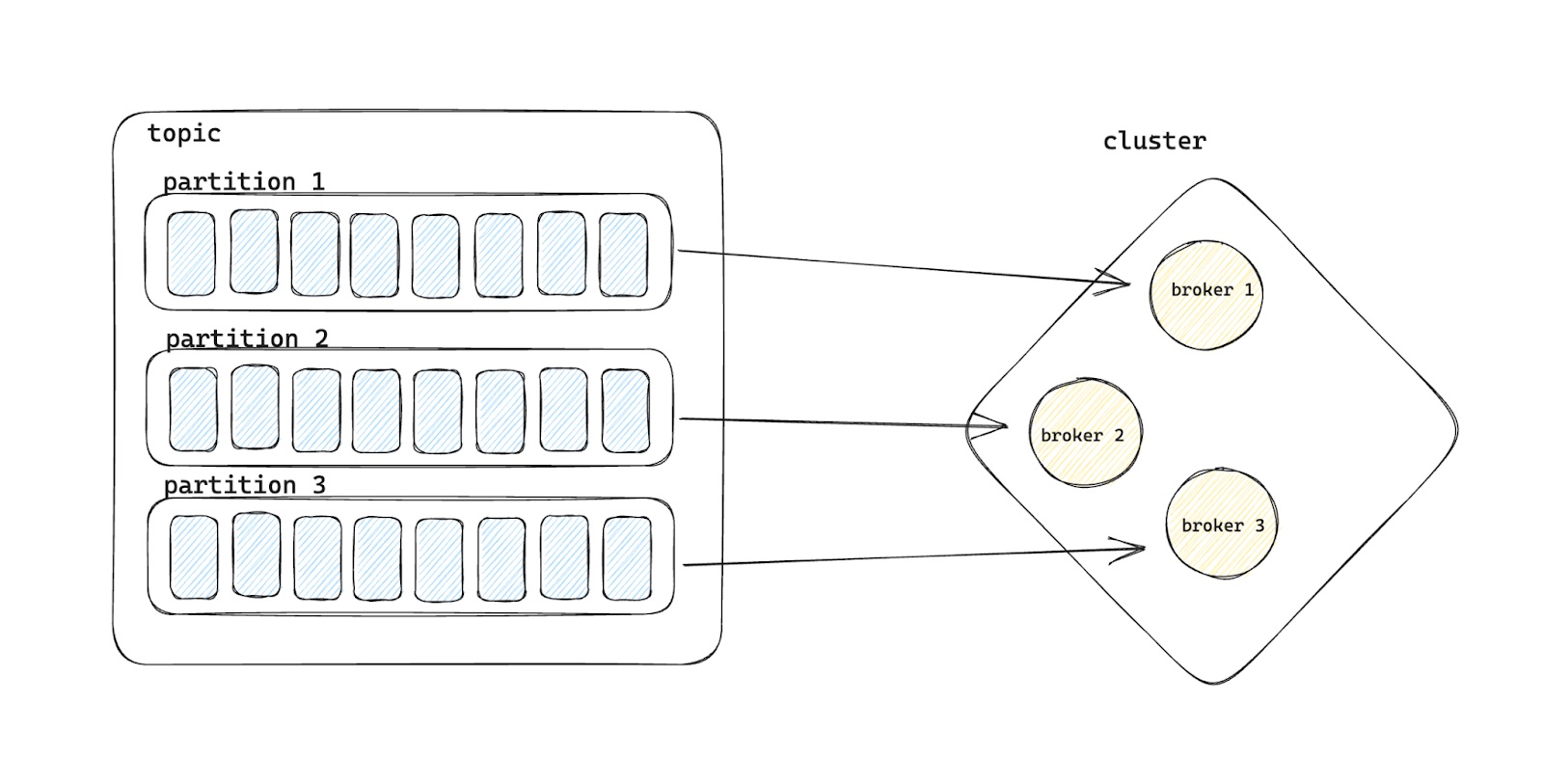
Dùng cách phân tán dữ liệu để xử lý chúng hiệu quả hơn
Là một tập hợp các Brokers hoạt động cùng nhau để tạo thành một hệ thống phân tán. Kafka sử dụng kiến trúc phân tán để mở rộng khả năng xử lý và lưu trữ dữ liệu.
Zookeeper của Kafka là gì?
Đây là một dịch vụ tập trung được sử dụng để duy trì thông tin cấu hình, tên và cung cấp dịch vụ nhóm. Nó là một máy chủ đơn (Single node) được sử dụng để duy trì kết nối TCP (Transmission Control Protocol - Giao thức điều khiển truyền vận), xử lý yêu cầu và phản hồi thông tin, đồng thời giám sát trạng thái của các công cụ trong hệ thống Kafka.
Zookeeper đóng vai trò quan trọng trong việc quản lý và lưu trữ thông tin về các Broker, Topic, Partition và Consumer Group trong Kafka Cluster. Nó cung cấp khả năng quản lý và phân phối các nhiệm vụ như Leader election, quản lý Metadata,..
Offset
Offset được sử dụng để đánh dấu một tin nhắn cụ thể trong một Partition và có thể được coi như một con số duy nhất để xác định vị trí của tin nhắn đó. Nó bắt đầu từ 0 cho tin nhắn đầu tiên trong Partition và tăng dần theo thứ tự cho các tin nhắn tiếp theo.
Offset có vai trò quan trọng trong việc đảm bảo tính nhất quán và theo dõi tiến trình xử lý của các Consumer. Khi một Consumer đọc tin nhắn từ một Partition, nó sẽ ghi nhớ Offset của tin nhắn cuối cùng mà nó đã đọc, tin nhắn tiếp theo thì nó sẽ bắt đầu từ Offset kế.
Producer
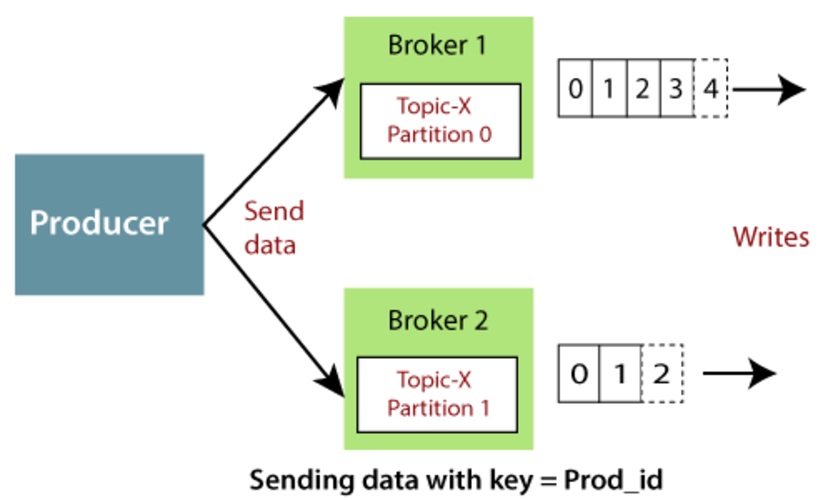
Producer có nhiệm vụ quan trọng là cung cấp dữ liệu để hệ thống xử lý
Đây là một thành phần trong hệ thống Kafka, có nhiệm vụ gửi dữ liệu (message) đến các chủ đề (topic) trong Kafka. Dữ liệu được gửi đến các Partition của Topic và được lưu trữ trên các Broker trong Kafka. Producer là nguồn cung cấp dữ liệu cho Kafka, và mọi người (Consumer) có thể đăng ký vào các Topic để nhận dữ liệu từ Producer.
Replication
Replication thực hiện việc sao chép và lưu trữ các tin nhắn trong một Partition. Mỗi Partition có một Leader Replication và một số Follower Replication. Leader là Broker chịu trách nhiệm xử lý các yêu cầu ghi và đọc từ Partition đó, trong khi Follower chỉ đơn giản là bản sao của Leader.
Ví dụ: Khi một tin nhắn được gửi tới một Partition, Leader Replication sẽ nhận và xử lý tin nhắn đó. Sau đó, sẽ sao chép tin nhắn đó và gửi cho các Follower để lưu trữ. Quá trình sao chép này đảm bảo rằng dữ liệu được nhân bản và đồng bộ giữa các Broker
Ứng dụng trong nhiều lĩnh vực của Kafka là gì?
Hệ thống này có nhiều ứng dụng trong thực tiễn, đóng vai trò rất quan trọng với nhiều ngành nghề như:
Kafka trong lĩnh vực Logistic

Logistics là ngành chuyên về vận chuyển và quản lý chuỗi cung ứng
Trong lĩnh vực Logistics, Kafka có thể được sử dụng để xử lý và truyền tải dữ liệu liên quan đến quá trình vận chuyển, giao nhận hàng hóa, và quản lý chuỗi cung ứng. Với Kafka, các hệ thống và ứng dụng trong lĩnh vực Logistics có thể gửi và nhận các tin nhắn liên quan đến thông tin vận chuyển, cập nhật vị trí hàng hóa, thông báo sự cố, và nhiều thông tin khác.
Kafka trong lĩnh vực Y học

Các bệnh viện hiện đang áp dụng kĩ thuật hiện đại trong khám chữa bệnh
Bệnh viện có thể sử dụng Kafka để xây dựng các cảm biến theo dõi thông tin sức khỏe của bệnh nhân như nhịp tim, huyết áp, thần kinh, nhiệt độ, và gửi thông tin này đến hệ thống theo thời gian thực để có thể phản ứng kịp thời khi có sự thay đổi.
Trong lĩnh vực Marketing Kafka có vai trò gì?

Ứng dụng công nghệ hiện đại vào quy trình tiếp thị và quảng bá sản phẩm
Kafka cho phép thu thập và xử lý dữ liệu từ nhiều nguồn khác nhau như website, ứng dụng di động, mạng xã hội và hệ thống CRM. Dữ liệu này có thể được sử dụng để theo dõi và phân tích hành vi tiêu dùng của khách hàng, tạo ra thông tin hữu ích và đưa ra quyết định Marketing nhanh chóng.
Ngoài ra Kafka có thể được sử dụng làm một hệ thống phân phối thông điệp trong các chiến dịch Marketing. Các thông điệp quảng cáo, thông báo sản phẩm mới, hoặc thông tin khuyến mãi có thể được gửi đến các kênh Marketing khác nhau thông qua Kafka, đảm bảo tính nhất quán và đồng bộ trong việc truyền tải thông điệp.
Lợi ích của Kafka là gì?
Cùng khám phá những lợi ích tuyệt vời của Kafka trong phần này nhé.
Nâng cao Throughput

Ứng dụng Kafka vào kinh doanh để tạo ra sản phẩm chất lượng
Throughput là khả năng của một hệ thống hoặc công ty để chuyển đổi và xử lý lượng dữ liệu hoặc sản phẩm trong một khoảng thời gian nhất định. Nó thường được sử dụng để đo hiệu suất và khả năng sản xuất của một doanh nghiệp. Thông qua Kafka, doanh nghiệp có thể nâng cao khả năng Throughput này, nhằm đáp ứng nhu cầu sản xuất hoặc tiếp nhận của khách hàng trong quá trình sản xuất.
Trang bị khả năng Frequency hiện đại
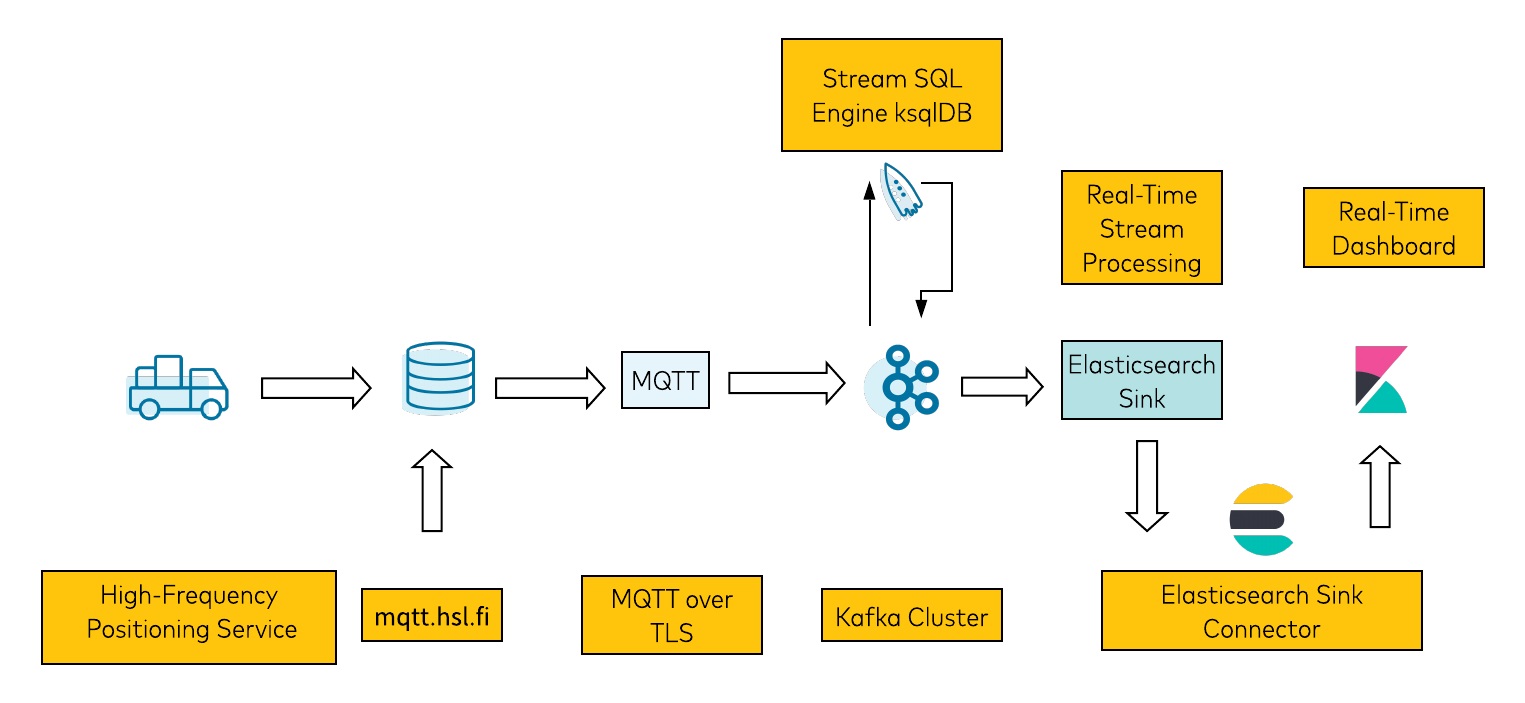
Khả năng xử lý dữ liệu thông minh với hiệu năng cao cấp của Kafka
Frequency là khả năng xử lý và xử lý dữ liệu theo thời gian thực. Kafka có thể được sử dụng để xử lý dữ liệu theo thời gian thực trong các ứng dụng như theo dõi hoạt động website, xử lý stream, tập hợp log, thu thập dữ liệu và nhiều ứng dụng khác. Với hiệu năng tốt, khả năng mở rộng và khả năng xử lý cao, Kafka đã trở thành một lựa chọn phổ biến cho việc xử lý dữ liệu phân tán.
Khả năng Scalability được đảm bảo
Scalability là khả năng mở rộng và xử lý một lượng lớn dữ liệu và thông tin. Kafka được thiết kế để xử lý một lượng lớn message và dữ liệu theo thời gian thực. Với kiến trúc phân tán và khả năng sao chép dữ liệu trong một Cluster, Kafka có thể mở rộng để đáp ứng nhu cầu xử lý tải lớn và lưu trữ dữ liệu an toàn.
Kafka có khả năng mở rộng theo hai chiều: mở rộng theo số lượng Producer và Consumer, và mở rộng theo khả năng xử lý và lưu trữ dữ liệu. Nó có thể xử lý đồng thời nhiều message từ nhiều nguồn khác nhau. Đồng thời, Kafka cũng có thể mở rộng bằng cách thêm Broker vào Cluster để tăng khả năng xử lý và lưu trữ dữ liệu.
Kafka hoạt động như thế nào?
Kafka hoạt động dựa trên mô hình Publish/subscribe, tương tự như các hệ thống Message khác. Các ứng dụng đóng vai trò là Poducer gửi các Message tới một Broker và thông báo rằng những Message này sẽ được xử lý bởi các ứng dụng khác đóng vai trò là Consumer. Các dữ liệu được gửi đến sẽ được lưu trữ trong một địa điểm gọi là Topic và sau đó các Consumer có thể subscribe vào Topic đó để lắng nghe những message này, nó có thể chứa các thông tin như giá trị cảm biến, hành động người dùng, v.v.
So sánh Kafka và RabbitMQ

So sánh hai hệ thống xử lý dữ liệu phổ biến nhất hiện nay
Tuy có những điểm tương đồng giữa hai hệ thống, nhưng cốt lõi của từng hệ thống vẫn có những nét riêng biệt, mà không thể thay thế cho nhau được. Cùng liệt kê một vài điểm khác biệt của Kafka và RabbitMQ như sau:
|
Tiêu chí |
RabbitMQ |
Kafka |
|
Kiến trúc tiếp cận |
Mô hình Message Broker |
Mô hình Publish/subscribe |
|
Lưu trữ |
Lưu trữ tin nhắn trong các hàng đợi (queues) |
Lưu trữ tin nhắn trong các Partition của Topic |
|
Hiệu suất |
Có khả năng xử lý lớn, nhưng hiệu suất của nó thường thấp hơn so với Kafka trong các tình huống với lưu lượng tin nhắn lớn. |
Được thiết kế để xử lý hàng triệu tin nhắn mỗi giây và có khả năng mở rộng tốt. Nó có thể xử lý dữ liệu với hiệu suất cao và hỗ trợ việc lưu trữ dữ liệu trong thời gian dài |
|
Ứng dụng |
Thích hợp cho các tác vụ xử lý tin nhắn có độ trễ thấp và yêu cầu tính toàn vẹn cao. Nó được sử dụng rộng rãi trong các ứng dụng liên quan đến hệ thống phân tán và kiến trúc dịch vụ (SOA) |
Thích hợp cho các tác vụ xử lý dữ liệu lớn và các luồng dữ liệu thời gian thực. |
Hướng dẫn chi tiết cách sử dụng Kafka thông qua Quarkus
Dùng Quarkus để tối ưu hóa dữ liệu và hỗ trợ xử lý thông tin
Quarkus là một framework Java dựa trên mã nguồn mở, được tối ưu hóa để chạy các ứng dụng Java trong môi trường container như Kubernetes. Nó được thiết kế để giúp phát triển ứng dụng Java nhanh hơn và tiết kiệm tài nguyên hơn trong môi trường đám mây.
Bên cạnh đó còn hỗ trợ Kafka hoạt động. Dưới đây là một số bước cần biết nếu mọi người muốn dùng Kafka.
Bước 1: Tạo dự án
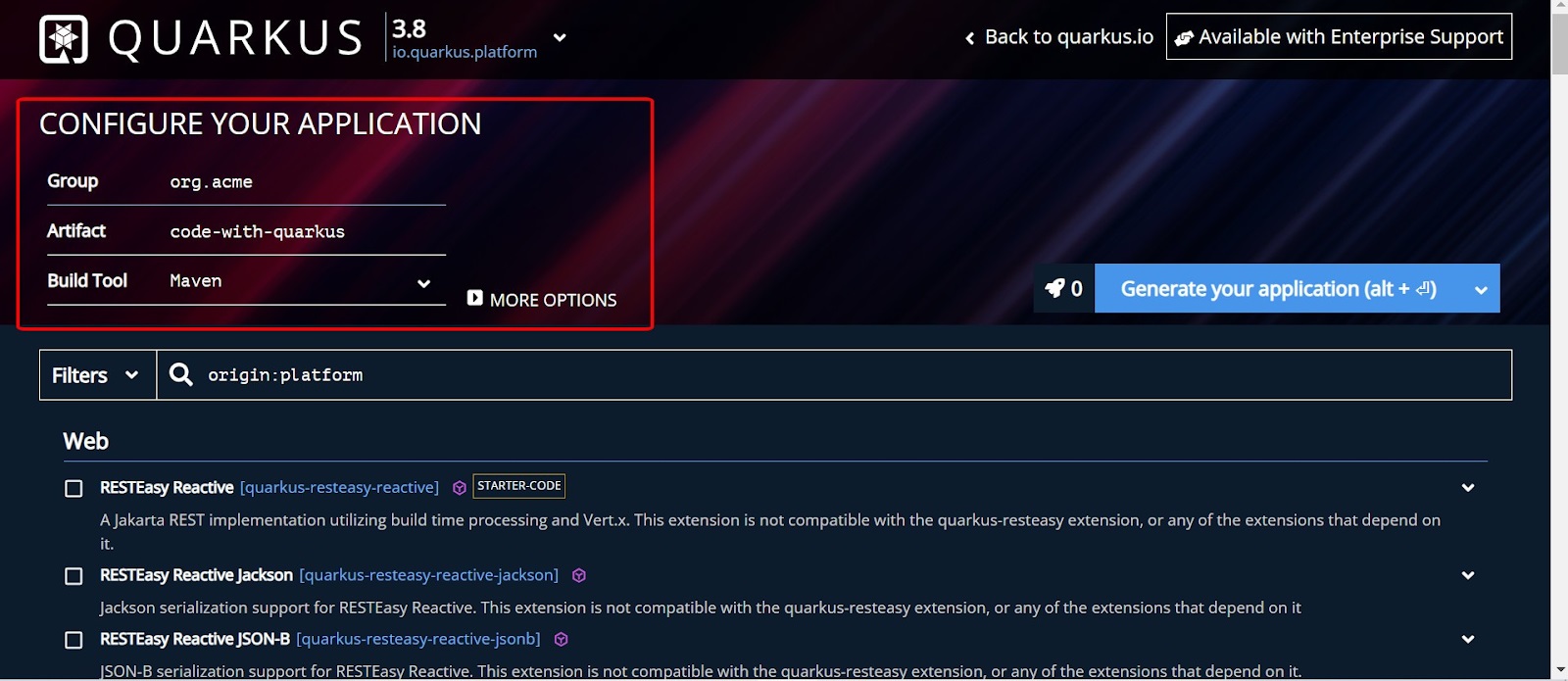
Điền những thông tin cần thiết để xử lý dữ liệu hiệu quả
Truy cập vào https://code.quarkus.io/, mọi người cần cung cấp các thông tin cấu hình Kafka như địa chỉ máy chủ Kafka, cổng, tên topic, và các thông số khác tùy thuộc vào yêu cầu của bạn.
- Nhập các thông tin cần thiết như Group, Artifact, Build Tool, và Version cho dự án của bạn.
- Chọn các Dependencies mà bạn muốn sử dụng trong dự án. Ví dụ, nếu bạn muốn sử dụng Kafka, hãy chọn Dependency "SmallRye reactive messaging".
- Nhấp vào nút "Generate your application" để tạo dự án.
- Tải xuống dự án dưới dạng file zip và giải nén nó.
- Mở dự án trong IDE của bạn, ví dụ như IntelliJ hoặc Eclipse.
- Bắt đầu viết mã trong dự án của bạn để xử lý các logic và chức năng mong muốn.
Bước 2: Tạo Model object

Tạo Model theo yêu cầu cá nhân để kích hoạt hệ thống
Trước tiên, người dùng cần tạo một Class đại diện cho Model của bạn. Sau đó, bạn có thể sử dụng đối tượng Model này trong các thành phần khác của ứng dụng, chẳng hạn như trong các Restful endpoint (điểm cuối Rest) hoặc các ứng dụng khác.
Bước 3: Tạo Producer
Mọi người cần tạo một class đại diện cho Producer của bạn. Tiếp theo thêm Annotation trên Class. Bên trong class, chúng ta đã thêm một Emitter, nó sẽ có nghĩa vụ gửi Message. Emitter được gắn vào Movies-out channel và sẽ gửi Message tới Kafka.
Bước 4: Tạo consumer trong Kafka là gì?
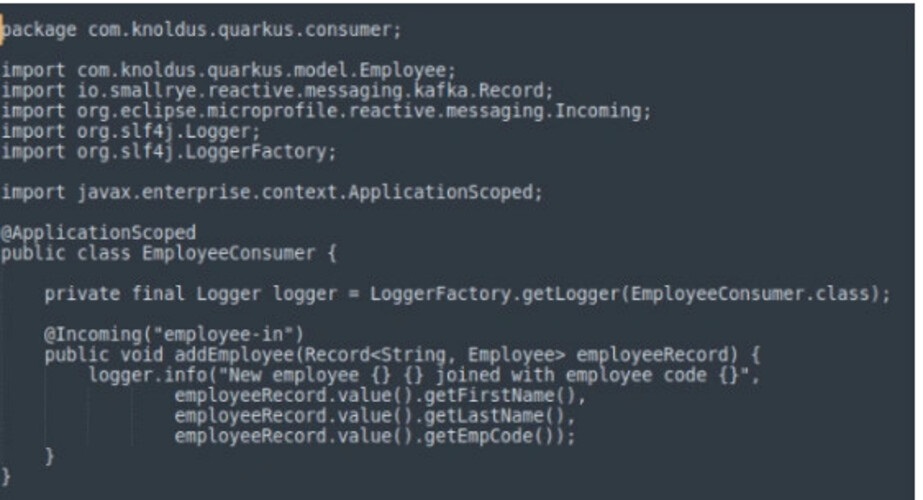
Thiết lập Consumer để sử dụng những tính năng trên Quarkus
Nếu muốn tạo một Consumer Employee, cần sử dụng annotation@Incoming("employee-channel") để xác định channel mà chúng ta muốn nhận Message. Trong trường hợp này, chúng ta đang nhận message từ channel có tên là "employee-channel". Bạn có thể triển khai xử lý các message nhận được.
Bước 5: Thiết lập Kafka
Đến bước này thì mọi người chỉ cần tạo tệp docker-compose.yaml vào thư mục gốc và thêm nội dung mà mọi người muốn Kafka xử lý.
Cách xử lý một số lỗi phổ biến khi sử dụng Kafka là gì?

Thỉnh thoảng hệ thống này cũng sẽ xảy ra một vài lỗi nhỏ
Tuy có nhiều tính năng ưu việt, nhưng không có một hệ thống nào mà không có vài khuyết điểm và Kafka cũng thế. Một vài lỗi mà người dùng có thể gặp khi làm việc với nó như:
- Lỗi khi kết nối tới Kafka Broker: Nếu gặp lỗi này, bạn cần kiểm tra xem các thông tin cấu hình như địa chỉ IP, cổng kết nối, và thông tin xác thực đã được cung cấp đúng chưa. Nếu thông tin cấu hình không chính xác, hãy sửa và thử kết nối lại.
- Lỗi khi subscribe vào Topic: hãy kiểm tra xem Topic đã tồn tại hay chưa. Nếu nó chưa được tạo, hãy tạo Topic trước khi subscribe. Ngoài ra, hãy đảm bảo rằng Consumer Group của bạn đã được tạo và đúng khi subscribe.
- Lỗi khi xử lý message: Khi Consumer nhận được message từ Kafka, có thể xảy ra lỗi trong quá trình xử lý. Trong trường hợp này, bạn cần xem xét các bước xử lý message của bạn và kiểm tra xem có lỗi nào trong quá trình này không. Hãy đảm bảo rằng mã logic xử lý message của bạn đã được kiểm tra và xử lý các trường hợp lỗi có thể xảy ra.
- Lỗi khi commit offset: Khi Consumer đã xử lý xong một message, nó cần Commit Offset để đánh dấu rằng message đã được xử lý. Nếu không thể tiếp tục làm việc do mắc lỗi này, hãy kiểm tra xem có lỗi trong quá trình commit không.
- Lỗi khi tái cân bằng Consumer Group: hay còn gọi là (Rebalance Consumer Group), khi có sự thay đổi như thêm hoặc xóa Consumer, có thể xảy ra lỗi này, hãy kiểm tra xem các Consumer đã được tạo và đăng ký vào group đúng cách. Nếu cần, hãy điều chỉnh số lượng Partition và Consumer trong nhóm, để tránh lỗi này.
Trong bài viết này tech24 đã tổng hợp những nội dung liên quan đến thắc mắc Kafka là gì?. Công nghệ càng phát triển thì đồng nghĩa với việc dân trí sẽ được gia tăng gấp nhiều lần, do có công nghệ hiện đại hỗ trợ. Những phương pháp thủ công đã không còn phù hợp và mất nhiều thời gian. Đó cũng là lý do mọi người cần thường xuyên cập nhật kiến thức về công nghệ, để làm việc tốt hơn. Hy vọng rằng bài viết này sẽ mang đến nhiều lợi ích cho mọi người nhé.